
Debugging Superpowers With the New js-libp2p Developer Tools
Discover how the new js-libp2p developer tools provide real-time debugging capabilities for js-libp2p and Helia nodes in both browsers and Node.js.



What’s new: Kubo v0.39 ships Provide Sweep as the default provider system. After testing as an opt-in experimental feature in v0.38 with no significant issues, it now comes with smart resume capabilities and memory optimizations. By grouping CIDs allocated to the same IPFS DHT servers and sweeping through keyspace regions systematically, nodes achieve 97% fewer DHT lookups with smooth, predictable resource usage.
Why it matters: Self-hosting a lot of content and publishing yourself as a provider becomes viable for regular users, businesses and organizations. Resource-constrained hardware (like Raspberry Pi) can now provide hundreds of thousands of CIDs; high-capacity nodes scale to hundreds of millions and beyond.
For years, IPFS nodes running Kubo hit a hard scalability wall: the legacy provider could only handle 5-10k CIDs before reprovide cycles couldn’t complete in time. Beyond that threshold, your content would gradually disappear from the IPFS DHT. The culprit? Each CID required its own 10-20 second DHT lookup, processed one at a time.
Provide Sweep changes everything. By batching CIDs that get allocated to the same DHT servers and sweeping through the keyspace systematically, we’ve unlocked dramatic efficiency gains. For a node providing 100k CIDs, this means a 97% reduction in lookup operations. Resource-constrained nodes can now handle hundreds of thousands of CIDs, while high-capacity nodes can scale to hundreds of millions and beyond—all with smooth, predictable resource usage distributed over time.
First introduced as an experimental opt-in feature in Kubo v0.38, Provide Sweep has been thoroughly tested in production without uncovering any significant bugs or showstoppers. Building on this success, Kubo v0.39 makes Provide Sweep the default provider system and includes smart resume capabilities to handle node restarts gracefully, along with memory optimizations for better performance at scale.
This post dives into how content routing actually works in IPFS, why the old approach created bottlenecks, and how batching unlocks DHT participation for self-hosting Kubo users. You’ll see real performance data and understand how Provide Sweep works in your node.
The DHT is no longer limited to providing just a few thousand CIDs. The following sections explain how this breakthrough works.
IPFS relies on content addressing: content is identified by its cryptographic hash (a CID) rather than its location. This decouples content identity from where it lives on the network, enabling powerful properties like verifiability, deduplication, and permanent addressing. However, it creates a fundamental discovery problem. When you have a CID, you know what you want, but not where to find it. Unlike HTTP where the URL contains the server address, a CID provides no location information whatsoever.
This is where content routing becomes essential: a distributed system that maps CIDs to the peers that can serve them. Nodes need two fundamental capabilities:
IPFS supports multiple content routing approaches. Two public systems are widely used, and organizations can also deploy private routing infrastructure:
The Amino DHT is a peer-to-peer distributed hash table for peer and content routing. The rest of this post focuses on the Amino DHT and how recent optimizations make providing content at scale practical.
IPNI
operates as a centralized index maintaining a
database of CID-to-provider mappings. This enables fast
single-hop lookups but comes with practical limitations. Recent service outages
demonstrate the fragility of centralized infrastructure. Additionally, advertising
content to IPNI from Kubo requires running additional infrastructure
(index-provider).
Organizations can also deploy private content routing infrastructure within their own networks, useful for enterprise deployments where content should only be discoverable within specific organizational boundaries. Private systems can use isolated DHT instances or custom routing mechanisms optimized for specific use cases, such as static peering or delegated routing over HTTP .
A Distributed Hash Table (DHT) is a self-organizing swarm of peers forming the abstraction of a distributed key-value store. The Amino DHT, previously known as the Public IPFS DHT, is IPFS’s original content routing system. The Amino DHT spec is based on the Kademlia DHT .
In the Kademlia keyspace, everything (peers, names, keys, and CIDs) gets mapped to a 256-bit identifier , typically using SHA2-256 hashing. Think of this identifier as the object’s address in the DHT.
The DHT works as a key-value store, which means values must be stored on real, reachable peers. The system stores objects on peers whose identifiers are “closest” to the object’s identifier. This “closeness” is measured using the XOR operation between the two binary identifiers, a mathematical way to calculate distance in this virtual space.
Each peer keeps records of its nearest neighbors in a routing table based on XOR distance. For more distant regions of the keyspace, peers maintain sparser routing information, knowing fewer peers as the XOR distance grows.
When a node searches for an object, it contacts its known peers that are closest to that object in XOR distance. Those peers will either return the object itself or point to even closer peers who might have it. This creates a chain of increasingly accurate directions until the object is found.
This routing approach is remarkably efficient: each node only needs to remember information about roughly log₂(N) other peers, and lookups complete in about log₂(N) steps, where N is the total number of nodes in the network.
The Amino DHT is a public network where peers can join and leave freely. This flexibility creates a challenge: if nodes storing information about content suddenly go offline, that content becomes undiscoverable. The solution is redundancy.
The Amino DHT uses a replication factor of 20 . When a node wants to store a value indexed at a particular key, it must find the 20 peers whose identifiers are closest to that key in XOR distance, then request each of these peers to store the key-value pair. This redundancy ensures the network remains robust even as peers constantly churn in and out.
It’s important to note that the DHT doesn’t store the actual content itself. Instead, it stores provider records : lightweight pointers that map each CID to a list of peer IDs that actually serve that content. Think of these as a directory linking what you’re looking for to where you can find it.
Provider records aren’t permanent. Since peers can go offline or stop hosting content at any time, the DHT implements an expiration mechanism . Each provider record has a time-to-live (TTL) of 48 hours. After this period, a peer’s entry is automatically removed from the provider list unless renewed.
To maintain their presence as content providers, nodes must periodically re-advertise their provider records. The majority of Amino DHT participants (e.g., Kubo) do this every 22 hours , well before the 48-hour expiration. This regular refresh serves two purposes: it keeps valid providers discoverable, and it ensures that as the network topology shifts with peer churn, provider records migrate to the peers that are now truly closest to the content identifier.
For more details on these system constants (22h and 48h), see the Provider Record Liveness Study (2022) .
The Amino DHT is designed to work in a fundamentally different way than centralized storage systems. These design decisions lead to different performance characteristics and operational behaviors. Here’s how they compare:
| Aspect | Centralized Store | Amino DHT |
|---|---|---|
| Lookup Speed | Single hop to known endpoint | Multiple hops |
| Load Balancing | Requires explicit infrastructure (load balancers, CDNs) | Natural distribution across peers with no coordination |
| Network Control | Full control over latency, geography, node quality | No guarantees: variable latency, unknown node locations, potential malicious actors |
| Scalability | Scales with operator investment | Scales organically with content and participants |
| Operational Burden | Operator handles synchronization, scaling, backups, expiration | Users handle redundancy and periodic reprovides |
| High-Throughput Reliability | Can be optimized for massive loads and high ingestion rates | Less reliable under very high load; depends on nodes performance |
| Sustainability | Vulnerable to defunding, service degradation, infrastructure failures | Self-sustaining through distributed operation; no dependency on continued funding |
The Core Tradeoff: The DHT sacrifices speed and predictability for resilience. It’s slower than hitting a known HTTP endpoint, but it creates a system that remains functional and sustainable even when half the network goes offline .
While the Amino DHT’s distributed architecture offers resilience, it comes with scalability challenges that become more apparent as IPFS usage grows. The core issue lies in how the provide and reprovide mechanisms work in practice. We focus on Kubo because it supports self-hosting and is the dominant user agent on the Amino DHT .
Kubo triggers provide operations in two situations:
Initial Provide: When new content enters your node (through ipfs add
,
Bitswap retrieval, or HTTP gateway fetch), Kubo checks if it matches your
provide
strategy
.
If it does, the CID is advertised to the DHT.
Reprovide Cycle: As a background task, Kubo ensures all CIDs matching your provide strategy are re-advertised every 22 hours, preventing them from expiring from the DHT.
Recall that providing content to the DHT requires finding the 20 closest peers to a CID and asking each to store a provider record. In Kubo prior to 0.39, this process happens sequentially: CIDs waiting to be provided sit in a queue, and each one undergoes a full Kademlia lookup to identify those 20 closest peers.
The main problem is timing. A single provide operation typically takes 10-20 seconds to complete (measurement data ). The bottleneck isn’t the actual storage of provider records, it is the lookup process itself. Since the DHT contains unreliable nodes that may timeout or fail to respond, finding 20 reachable closest peers requires patience and retries.
This sequential approach creates a practical ceiling: if new content arrives faster than Kubo can provide it, the queue grows indefinitely. The system simply can’t keep up.
The reproviding process faces an even tighter constraint. Every 22 hours, Kubo attempts to reprovide all CIDs matching its provide strategy , adding them to a dedicated queue and processing them one by one using the same slow provide mechanism.
The math is unforgiving: at 15 seconds per provide operation, Kubo can only reprovide 5,280 CIDs within the 22-hour window. If reproviding takes longer than 22 hours, the next cycle is skipped entirely, and provider records begin expiring from the DHT after their 48-hour TTL elapses.
For nodes hosting more than a few thousand CIDs, this becomes unsustainable and their content gradually disappears from the DHT.
The Accelerated DHT Client was developed to address these limitations through a brute-force approach: maintain a complete map of the network.
This opt-in client periodically crawls the entire DHT, contacting every participating node to build a snapshot of all peer addresses. With this snapshot in memory, finding the 20 closest peers to any key becomes instant: no messages, no timeouts, just a local lookup.
The tradeoff is resource intensity. Storing information about 10,000 peers in memory is manageable, but crawling the network is expensive. By default, the client performs a full network crawl every hour, sending multiple messages to every single DHT server. This requires substantial bandwidth, opens numerous connections, and operates with high parallelism.
While the accelerated client makes providing faster, it doesn’t make it more resource efficient unless you’re providing an extremely large number of CIDs. It’s a solution for dedicated high-profile server nodes with resources to spare, but impractical for smaller scale IPFS users who want to participate in the network without such overhead.
The traditional approach to providing treats each CID independently, requiring a separate DHT lookup for every provider record. This optimization takes advantage of a simple observation: CIDs that are close together in the Kademlia keyspace share the same closest peers. By pooling nearby CIDs and providing them consecutively, we can dramatically reduce the number of lookups needed.
The mathematics behind this is straightforward. Consider the pigeonhole principle: if you have far more CIDs to provide than there are DHT servers in the network, then each server must be allocated multiple CIDs. Since each CID must be stored on 20 servers (the replication factor), and there are approximately 10,000 active DHT servers, a node providing hundreds of thousands of CIDs will send dozens or even hundreds of provider records to the same servers. Rather than discovering these servers repeatedly through separate lookups, Provide Sweep finds them once and delivers all relevant provider records together.
The Provide Sweep system in Kubo handles two types of workloads: periodically reproviding existing content before old DHT records expire, and providing fresh CIDs when users import new data to their IPFS node.
Reprovide Sweep transforms the inefficient reproviding cycle into a systematic traversal of the Kademlia keyspace. Instead of processing CIDs in arbitrary order and performing a lookup for each one, it organizes all CIDs by keyspace regions and sweeps through these regions sequentially.
Rather than attempting to reprovide all CIDs at once, which would create a massive spike in network and CPU usage, Reprovide Sweep schedules region reprovides evenly across the 22-hour reprovide interval. This transforms what was once a resource-intensive burst into a smooth, continuous background process that distributes the load over time.
When it’s time to reprovide a keyspace region, the system explores that region to discover all peers whose identifiers match the region prefix. Each region is defined by a keyspace prefix and is sized to contain at least 20 peers, ensuring there are always enough nodes to satisfy the DHT’s replication factor. The system then allocates all provider records whose CIDs fall within this region to their 20 closest peers. This batching is the key efficiency gain: instead of running separate lookups for CIDs that happen to be near each other in the keyspace, we discover the relevant peers once and deliver all applicable provider records together.
The efficiency gains are substantial. In a DHT with approximately 10,000 active peers, Provide Sweep caps the number of lookups at around 3,000, regardless of how many CIDs you’re providing. Compare this to the traditional approach, which requires one lookup per CID. For a node providing 100,000 CIDs, this represents a 97% reduction in lookup operations.
This optimization makes reproviding practical even for resource-constrained nodes. The work is spread evenly over time, and the number of lookups is bounded by whichever is smaller: network size or number of CIDs. The system can reprovide hundreds of thousands of CIDs using low concurrency and modest hardware, handling collections that were previously impossible to maintain on the DHT.
Provide Sweep handles node restarts gracefully by remembering where it left off in the sweep cycle. When you restart Kubo, the daemon identifies which keyspace regions haven’t been reprovided in the last 22 hours and reprovides only those regions as soon as possible after startup, ensuring your content remains discoverable.
This targeted approach optimizes both network and CPU usage: instead of reproviding all content or restarting from scratch, the node focuses resources exclusively on the regions that need refreshing.
The traditional provide queue processed new CIDs one at a time, requiring a separate DHT lookup for each. This sequential approach suffered from the same inefficiencies that plagued reproviding: each lookup took 10-20 seconds, and the queue could easily grow faster than it could be drained.
The batched provide queue applies the same keyspace region grouping strategy to newly announced content. As CIDs are added to the provide queue, they’re automatically organized by their keyspace region rather than processed in simple first-in-first-out order. When the system is ready to perform a provide operation, it pops all CIDs from the same region as the head of the queue and provides them together in a single batch.
This approach delivers the same efficiency gains as Reprovide Sweep: peers in a keyspace region are discovered once, then all relevant provider records are delivered together. The result is dramatically faster processing of the provide queue, enabling nodes to keep up with content ingestion rates that would have been impossible under the old system.
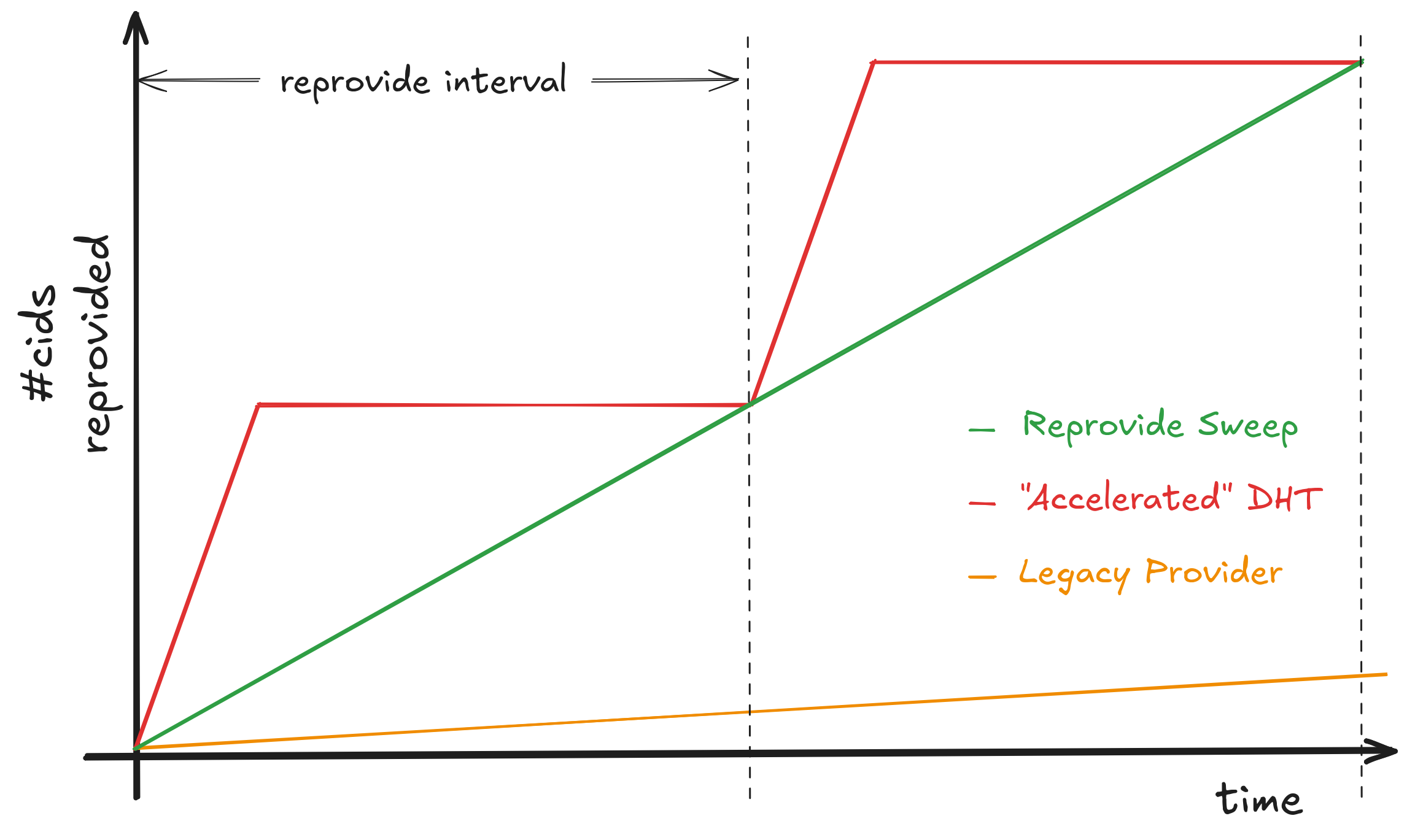
The diagram above illustrates how each provider system handles the reprovide cycle differently:
Legacy Provider (orange line): The legacy system cannot provide content fast enough to keep pace with the number of CIDs requiring reprovision. At 15 seconds per provide operation and processing CIDs sequentially, it can only handle about 5,280 CIDs in a 22-hour reprovide interval. For nodes with larger collections, the backlog grows continuously, and provider records eventually expire from the DHT after 48 hours.
Accelerated DHT Client with Legacy Provider (red line): This configuration combines the legacy sequential provide system with the Accelerated DHT Client. With a complete network map in memory, the accelerated client eliminates DHT lookups during provides, allowing the legacy provider to reprovide all CIDs as quickly as possible. This creates a concentrated spike at the beginning of each reprovide interval. While effective at completing the work, this burst approach creates temporary peaks in resource usage—high CPU load, network bandwidth consumption, and numerous concurrent connections.
Reprovide Sweep with Standard DHT Client (green line): The sweeping provider uses the standard DHT client but distributes the reprovide workload evenly across the entire 22-hour interval. By processing keyspace regions on a schedule and batching CIDs that share the same closest peers, it maintains constant, predictable resource usage. The work completes on time without spikes, making efficient reproviding accessible even to resource-constrained nodes.
Both the Accelerated DHT Client and Reprovide Sweep successfully complete all reprovides within the interval, but Reprovide Sweep achieves this with dramatically lower resource requirements and smoother operation.
The following metrics come from a controlled experiment on the live Amino DHT:
Test Configuration:
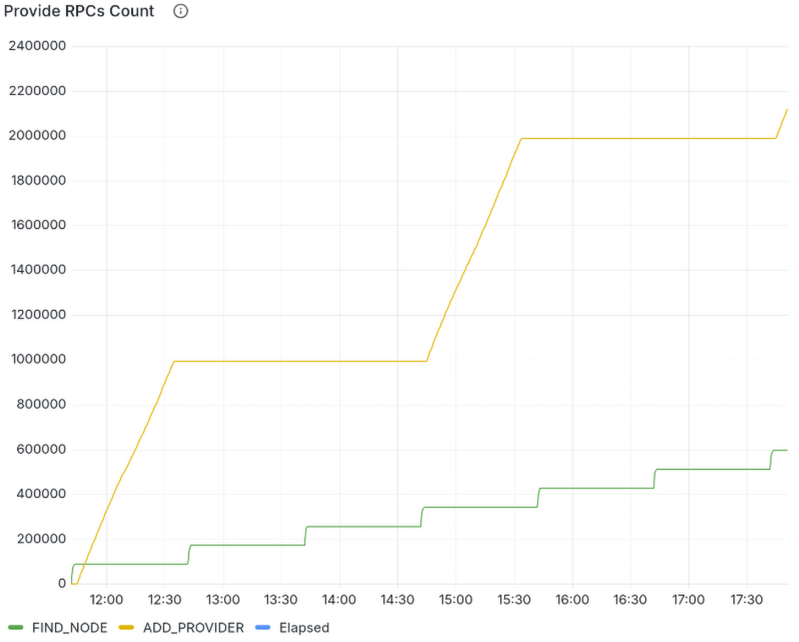
Accelerated DHT Client
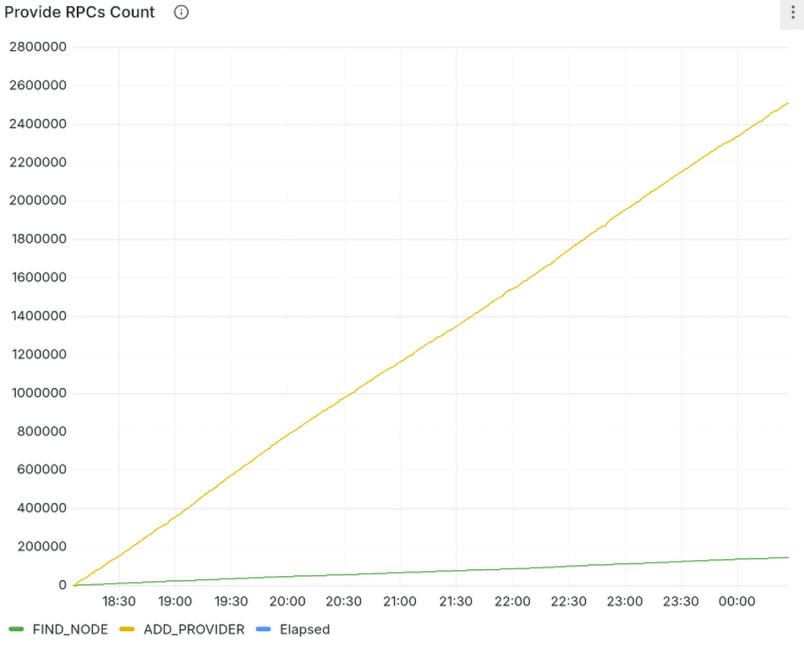
Reprovide Sweep
The graphs above show slightly more than two complete reprovide cycles for each system.
Understanding the Metrics:
The yellow line represents ADD_PROVIDER
RPCs sent to the Amino DHT. Each
RPC asks a DHT server to store a provider record for a specific CID. With a
replication factor of 20, we expect up to 20 ADD_PROVIDER requests per CID:
one for each of the 20 closest peers. In practice, both systems send fewer than
20 requests per CID because they skip unresponsive nodes.
The green line shows FIND_NODE
RPCs sent during DHT lookups. When
discovering which peers are closest to a given key, a node sends multiple
FIND_NODE requests to traverse the network and locate the target peers.
Accelerated DHT Client Behavior:
The Accelerated DHT Client exhibits the characteristic burst pattern. The
yellow ADD_PROVIDER line shows intense activity concentrated at the start of
each 3-hour window as it races to reprovide all 100,000 CIDs as quickly as
possible. CPU, memory, and network bandwidth all spike sharply, then drop once
the work completes.
The green FIND_NODE line reveals regular hourly bumps corresponding to the
Accelerated DHT Client’s network crawls. During these crawls, the client
contacts every DHT server to build its complete network map. Outside of crawls,
no DHT lookups are performed, all routing happens from the cached snapshot,
which is why the line remains flat between crawls.
Reprovide Sweep Behavior:
Reprovide Sweep shows fundamentally different patterns. The yellow
ADD_PROVIDER line grows smoothly and steadily across the entire interval,
demonstrating consistent resource usage distributed evenly over time. Even with
just a single worker thread (representing extremely low resource allocation
compared to Kubo’s default
)
Reprovide Sweep successfully reprovides all 100,000 CIDs within the 3-hour
window.
The green FIND_NODE line shows gradual, regular growth as the node explores
the keyspace region by region. This includes both the lookups needed for
providing and the background requests used to maintain the DHT routing table.
The growth rate is dramatically lower than the Accelerated DHT Client’s hourly
crawl spikes.
Provider Record Replication:
Reprovide Sweep sends slightly more provider records per CID than the Accelerated DHT Client (approximately 12 vs 10 replicas per CID). This difference stems from their responsiveness thresholds. The Accelerated DHT Client is more strict: once it has enough responsive providers, it stops trying to reach slower peers. Reprovide Sweep attempts to send records to all 20 closest peers, even if some are slower to respond, as long as they’re reachable.
Network Efficiency at Scale:
The efficiency gap becomes clear when examining FIND_NODE request volumes:
Reprovide Sweep: Approximately 60,000 FIND_NODE requests to sweep the
full keyspace, plus 3,300 requests per hour for routing table maintenance. Over
a standard 22-hour interval, this totals roughly 132,000 requests.
Accelerated DHT Client: Approximately 85,000 FIND_NODE requests per
hourly network crawl. With 22 crawls over the reprovide interval, this totals
roughly 1.87 million requests, an order of magnitude more than Reprovide Sweep.
Important Context:
When providing very large numbers of CIDs (hundreds of thousands or millions),
the ADD_PROVIDER requests dominate total network traffic, dwarfing the
FIND_NODE overhead. At this scale, the network performance of both systems
converges in terms of total bandwidth, though the patterns remain different:
Accelerated is spiky, Reprovide Sweep is regular.
Additionally, if users make content routing queries (peer or content lookup),
the standard DHT client used by Reprovide Sweep will generate additional
FIND_NODE requests to perform those lookups. The Accelerated DHT Client
serves these queries from its cached network map without additional requests.
This is by design: the Accelerated client trades continuous crawling overhead
for zero-latency lookups.
Reprovide Sweep is now the default provider in Kubo v0.39. If you’re running v0.39 or later, you’re already using it. No configuration changes are needed.
Note on provide timing: Provide operations are asynchronous. When you add content
or trigger provides, the command returns immediately while the actual DHT advertising
happens in the background. Use ipfs provide stat to monitor the provide queue and
verify when your content has been fully advertised to the network.
Provide Sweep ships with sensible defaults that work well for most users. However, if you’re providing millions of CIDs or more, you should increase the number of provide workers to handle the higher throughput.
The key setting to adjust is Provide.DHT.MaxWorkers. For guidance on optimal
values for your scale, see the configuration
documentation
.
Reprovide Sweep includes detailed statistics and monitoring capabilities designed specifically for the sweeping architecture, providing much deeper visibility than the legacy provider.
The ipfs provide stat command exposes detailed metrics about your node’s providing
operations. Use --all to see the complete state and --compact for condensed formatting:
$ ipfs provide stat --all --compact
Schedule: Connectivity:
CIDs scheduled: 67M (67,704,411) Status: online (2025-10-31 15:30:58)
Regions scheduled: 260
Avg prefix length: 8.0 Queues:
Next region prefix: 00111101 Provide queue: 0 CIDs, 0 regions
Next region reprovide: 19:46:47 Reprovide queue: 0 regions
Network: Timings:
Avg record holders: 12.2 Uptime: 4h15m43.5s (2025-10-31 15:30:48)
Peers swept: 1,707 Current time offset: 17h0m41.3s
Full keyspace coverage: false Cycle started: 2025-10-31 02:45:50
Reachable peers: 1,204 (70%) Reprovide interval: 22h0m0s
Avg region size: 33.8
Replication factor: 20 Operations:
Ongoing provides: 0 CIDs, 0 regions
Workers: Ongoing reprovides: 2.1M CIDs, 8 regions
Active: 8 / 1,024 (max) Total CIDs provided: 1M (1,721,199)
Free: 496 Total records provided: 45M (45,094,206)
Workers stats: Periodic Burst Total provide errors: 0
Active: 8 0 CIDs provided/min/worker: N/A
Dedicated: 512 16 CIDs reprovided/min/worker: 15,668.8
Available: 1,000 512 Region reprovide duration: 1m22.2s
Queued: 0 0 Avg CIDs/reprovide: 18,693.2
Max connections/worker: 20 Regions reprovided (last cycle): 74
You can read more about these metrics in the Provide stats documentation .
These statistics help you spot problems early, validate efficiency gains, and troubleshoot issues. For example, if CIDs you just added aren’t available yet on the Amino DHT, you can quickly determine whether it’s due to queue backlog, provide failure, or your node being disconnected.
For reference, the legacy provider shows more basic stats:
$ ipfs provide stat
TotalReprovides: 3M (3,244,981)
AvgReprovideDuration: 2.15ms
LastReprovideDuration: 1h56m40.242914s
LastReprovide: 2025-09-30 17:57:44
Kubo exposes Prometheus metrics for both the legacy and new provide systems, allowing you to compare their performance side by side.
The up-to-date list of provide metrics can be found in the metrics documentation . Metric names may change between Kubo versions, so consult the documentation for your specific version.
In Kubo 0.39, metrics for comparing systems are:
provider_provides_totalprovider_reprovider_provide_count and
provider_reprovider_reprovide_countDue to different providing strategies, do not compare instantaneous provide rate
or throughput. Instead, compare total provides completed over multiples of the
reprovide interval (22h by default, configured via Provide.DHT.Interval
).
Provide Sweep distributes work evenly across the interval and should complete
dramatically more provides than the legacy system WITHOUT the Accelerated DHT Client.
When comparing these metrics between a Kubo node using the legacy provider WITH Accelerated DHT Client enabled versus one using Provide Sweep, you should expect to see patterns similar to the diagram below:
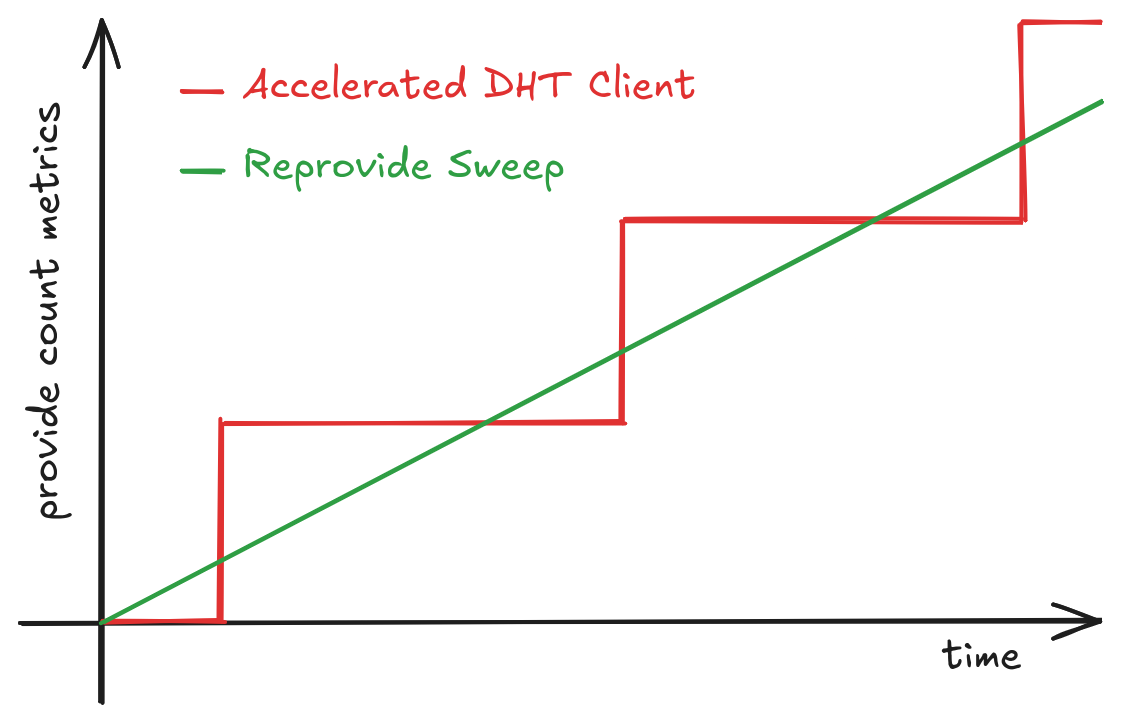
If you need to revert to the legacy provider in v0.39, you can disable the Sweep system with:
ipfs config --json Provide.DHT.SweepEnabled false
Alternatively, edit your Kubo configuration file directly. See the Provide configuration documentation for details.
After disabling, restart your Kubo node for the change to take effect.
Note: The legacy provider will remain available for several releases to allow time for migration and ensure compatibility. However, we strongly recommend using Provide Sweep for its superior performance and resource efficiency. Any future deprecation will be announced well in advance.
If you’re currently using the Accelerated DHT Client, we recommend disabling it when you enable Provide Sweep:
ipfs config --json Routing.AcceleratedDHTClient false
While the two features are technically compatible, running them together has trade-offs:
What happens when both are enabled:
Drawbacks of keeping Accelerated DHT Client enabled:
Benefits of keeping both enabled:
Bottom line: Do not use the Accelerated DHT Client on consumer networks or home internet. The network crawls can crash routers or trigger ISP throttling. Only use it in server rooms or datacenters with appropriate infrastructure, and only when your application specifically requires 0-RTT peer discovery or 1-RTT content discovery. Most users should rely on Provide Sweep alone, which delivers efficient content routing without the resource overhead.
Provide Sweep fundamentally changes who can participate effectively in the Amino DHT. Previously, only high-powered nodes with substantial resources could reliably provide content at scale. With these optimizations, content routing becomes accessible to a much broader range of users and use cases.
Desktop users and home servers can now provide at scale. Whether you’re running Kubo on a laptop, desktop computer, or a Raspberry Pi, you can now maintain hundreds of thousands of provider records on the DHT without overwhelming your system. The distributed, time-smoothed approach means providing no longer requires dedicated server hardware or constant high resource availability. With the legacy provider, nodes hosting large collections often couldn’t complete reprovide cycles within the 22-hour window, causing provider records to gradually expire from the DHT. Provide Sweep’s efficiency means your content remains consistently findable, even as your collection grows.
Reconsider the Accelerated DHT Client. If you enabled the Accelerated DHT Client primarily to handle providing large content collections, you can now turn it off and reclaim significant system resources. The hourly network crawls consume substantial bandwidth and memory that most users no longer need. Keep it enabled only if your application specifically requires blazing fast initial provides or near-instant peer or content discovery, for example if you’re running a caching layer in front of the DHT for delegated routing. For typical users, Provide Sweep is sufficient on its own. The Sweep eliminates the need for the Accelerated DHT Client when reproviding and makes provides more resource efficient, though they take longer since a DHT lookup is still required.
The following improvements are under consideration for future development. These represent areas where we see potential for further optimization, though implementation depends on available resources and community priorities.
If you operate at a scale where any of these optimizations would provide significant value to your deployment, Shipyard is open to discussing devgrants to prioritize their implementation.
IPNS records currently use the legacy sequential provider approach rather than sweep-based batching. Most users publish only a few IPNS names, so the existing logic performs adequately and batching would provide minimal benefit.
Large-scale providers publishing hundreds or thousands of IPNS names could benefit from applying sweep logic to IPNS records.
Currently, Reprovide Sweep uses static timeouts when contacting DHT peers. If a peer is slow or offline, your node waits for the full timeout before moving on, wasting time and resources.
The opportunity: Implement adaptive timeouts that fail faster on unresponsive peers and strategically skip slow peers when resource and time are limited. This trades slightly fewer replicas for significant gains in speed and resource efficiency.
Currently, when Reprovide Sweep moves between adjacent keyspace regions, it performs fresh DHT lookups even though many of the closest peers are likely the same or nearby. This represents an opportunity for significant optimization.
The opportunity: By caching peers discovered during sweeps in the routing table, the system can reuse peer information across adjacent regions. This would dramatically reduce the number of DHT lookups needed not just for providing operations, but for all DHT routing operations including peer and content discovery. The result would be faster provides, lower resource usage, and significantly reduced latency for general DHT queries.
We’re actively gathering feedback from the IPFS community about future improvements and priorities. If you have thoughts on these potential optimizations, encounter performance issues, or have feature requests, please:
Your feedback helps us focus development effort where it will have the most impact.
Discover how the new js-libp2p developer tools provide real-time debugging capabilities for js-libp2p and Helia nodes in both browsers and Node.js.

Update from Shipyard on our efforts to make IPFS work on the Web.


Our free IPFS tools and integrations have over 75 million monthly active users around the globe.
Help Fund Shipyard